About
A self taught data scientist and machine learning engineer with a background in Computer Science Engineering and over 2 years of experience in the AI/ML industry. My work interests include Applied Machine and Deep Learning, Generative AI, Reinforcement Learning and MLOps. At Genpact, I am working with the AI/ML Practice team to develop cutting edge solutions leveraging Generative AI. I also engage myself in developing custom finetuned Vision, Language and Multimodal solutions for variety of usecases in Healthcare, Manufacturing, Finance and Retail. As a part of R&D I participate in publishing our research work at top conferences and also patenting solutions with the core team.





















Work Experience
Skills
Check out my latest work
I've worked on a variety of projects, from simple websites to complex web applications. Here are a few of my favorites.
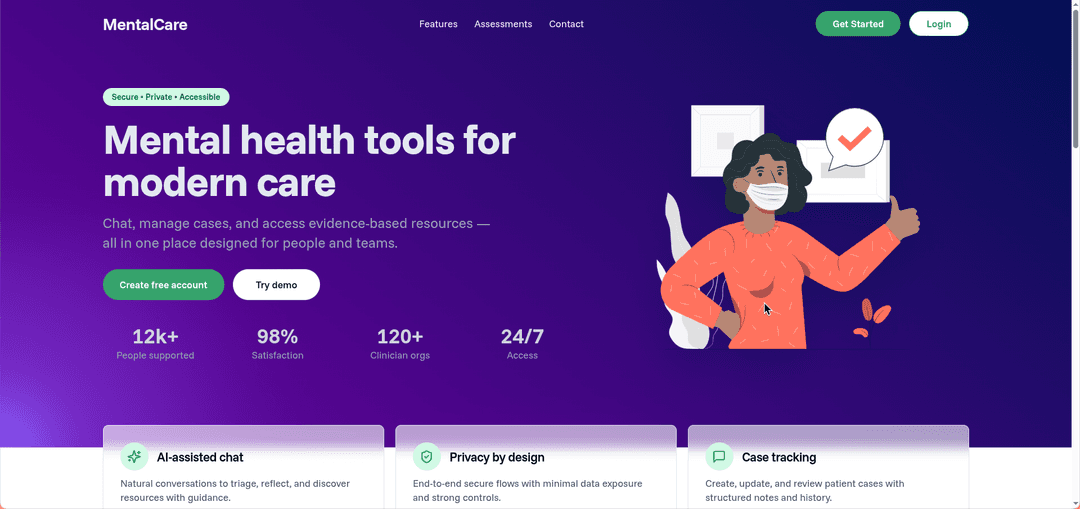
Qwen Mental Health Chatbot System
Finetuned the Qwen 3 4B Thinking model using an open-sourced Mental Health dataset from Huggingface. Built a FastAPI application to wrap the fine-tuned model with performant inference server and memory to persist user conversations. Added Patient, Cases and User handling to create an End-to-end mental health chatbot application.
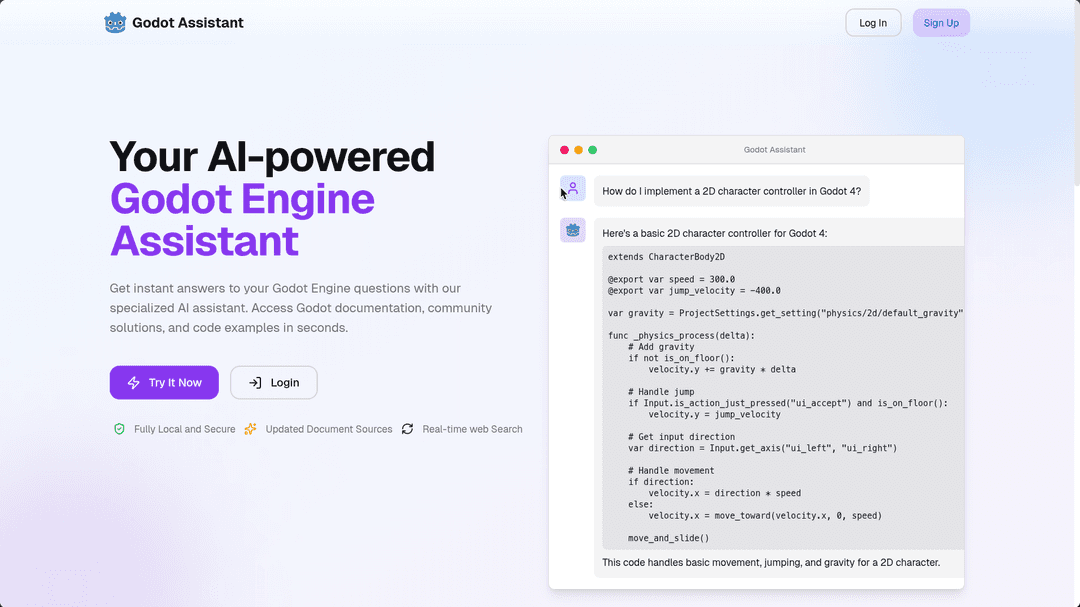
Godot RAG Assistant
Developed an agentic RAG application for Godot Documentation QnA Assiatent, to help Godot developers to quickly learn/debug games. Uses godot docs, Huggingface Godot qna dataset and other internet sources in real-time to answer queries. Built a simple UI using Chainlit. Currently working on building a proper UI using NextJS.

Gemini Mail Assistant
A Gemini app that summarizes your daily mails from Gmail.
Verified Skills
- Sep 2024D
Fully Automated MLOps
Datacamp - Sep 2024D
MLOps Concepts
Datacamp - Sep 2024D
MLOps Deployment and Life Cycling
Datacamp - Jun 2022D
Data Scientist with Python
Datacamp - Jul 2022D
Data Manupulation with Python
Datacamp - Jul 2023J
Deep Learning with PyTorch: Zero to GANs
Jovian - Mar 2023J
Machine Learning with Python: Zero to GBMs
Jovian - Apr 2021G
Google Cloud Training - Cloud Engineering Fundamentals, Cloud Application Development, Cloud ML-AI Google Cloud Training - Cloud Engineering Fundamentals, Cloud Application Development
Google Cloud - Jun 2020C
Java Programming: Problem Solving with Software
Coursera
Articles and Papers
Building a Multi-Vector Chatbot with LangChain, Milvus, and Cohere
In the fast-growing area of digital healthcare, medical chatbots are becoming an important tool for improving patient care and providing quick, reliable information. This article explains how to build a medical chatbot that uses multiple vectorstores. It focuses on creating a chatbot that can understand medical reports uploaded by users and give answers based on the information in these reports. Additionally, this chatbot uses another vectorstore filled with conversations between doctors and patients about different medical issues. This approach allows the chatbot to have a wide range of medical knowledge and patient interaction examples, helping it give personalized and relevant answers to user questions. The goal of this article is to offer developers and healthcare professionals a clear guide on how to develop a medical chatbot that can be a helpful resource for patients looking for information and advice based on their own health reports and concerns.
Self Hosting RAG Applications On Edge Devices with Langchain and Ollama–Part II
In the second part of our series on building a RAG application on a Raspberry Pi, we’ll expand on the foundation we laid in the first part, where we created and tested the core pipeline. In the first part, we created the core pipeline and tested it to ensure everything worked as expected. Now, we’re going to take things a step further by building a FastAPI application to serve our RAG pipeline and creating a Reflex app to give users a simple and interactive way to access it. This part will guide you through setting up the FastAPI back-end, designing the front-end with Reflex, and getting everything up and running on your Raspberry Pi. By the end, you’ll have a complete, working application that’s ready for real-world use.
Self Hosting RAG Applications On Edge Devices with Langchain and Ollama – Part I
This article follows that journey, showing how to transform this small device into a capable tool for smart document processing. We’ll guide you through setting up the Raspberry Pi, installing the needed software, and building a system to handle document ingestion and QnA tasks. By the end, you’ll see how even the smallest tech gadgets can achieve impressive results with a bit of creativity and effort.
RAG Application using Cohere Command-R and Rerank – Part 2
In the previous article, we experimented with Cohere’s Command-R model and Rerank model to generate responses and rerank doc sources. We have implemented a simple RAG pipeline using them to generate responses to user’s questions on ingested documents. However, what we have implemented is very simple and unsuitable for the general user, as it has no user interface to interact with the chatbot directly. In this article, we will modularize the codebase for easy interpretation and scaling and build a Streamlit application that will serve as an interface to interact with the RAG pipeline. The interface will be a chatbot interface that the user can use to interact with it. So, we will implement an additional memory component within the application, allowing users to ask follow-up queries on previous responses.
RAG Application with Cohere Command-R and Rerank – Part 1
The Retrieval-Augmented Generation approach combines LLMs with a retrieval system to improve response quality. However, inaccurate retrieval can lead to sub-optimal responses. Cohere’s re-ranker model enhances this process by evaluating and ordering search results based on contextual relevance, improving accuracy and saving time for specific information seekers. This article provides a guide on implementing Cohere command re-ranker model for document re-ranking, comparing its effectiveness with and without the re-ranker. It uses a pipeline to demonstrate both scenarios, providing insights into how the re-ranker model can streamline information retrieval and improve search tasks.
A Beginner’s Guide to Evaluating RAG Pipelines Using RAGAS
In the ever-evolving landscape of machine learning and artificial intelligence, the development of language model applications, particularly Retrieval Augmented Generation (RAG) systems, is becoming increasingly sophisticated. However, the real challenge surfaces not during the initial creation but in the ongoing maintenance and enhancement of these applications. This is where RAGAS—an evaluation library dedicated to providing metrics for RAG pipelines—comes into play. This article will explore the RAGAS library and teach you how to use it to evaluate RAG pipelines.
Get in Touch
Want to chat? Just shoot me a dm with a direct question on twitter and I'll respond whenever I can. I will ignore all soliciting.